By Elizabeth Gallagher, India Kerle, Cath Sleeman and Jack Vines

Introduction
There is no publicly available data on the skills that are commonly required in UK job adverts. As a result, there is very little understanding of either the skill specialities that exist in different regions in the UK or the skills required for given occupations. Considering this, Nesta set out to start collecting UK job adverts and developing algorithms to extract structured information from them in 2021. Two years on, Nesta’s Open Jobs Observatory (OJO) has collected over five million job adverts.
This project helps us to provide insights on a multitude of questions about job advertisements and the skills within them, such as:
- Which regions or occupations have the highest percentage of all UK job adverts?
- What are the common skills required for each occupation?
- Which occupations have similar skills required?
- What are the regional differences in commonly required skills?
We have recently enhanced our algorithm that extracts skills from job adverts and have made it open source in our new Skills Extractor Library. This Python package allows any user to extract skill phrases from the text of job advertisements and map these onto a standardised list of skills, using an existing expertly curated skills taxonomy. By mapping our extracted skill phrases onto an existing taxonomy, we can standardise the skills which might otherwise be described using slightly different wordings. For example, the skill phrases “team supervision” or “supervision of a team” could both be mapped to “supervise a team”. At present, skill phrases can be mapped onto one of two taxonomies that have been created by other organisations: the European Commission’s European Skills, Competences, and Occupations (ESCO) and Lightcast’s Open Skills.
In this article, we will discuss how our Skills Extractor Library works, how to use it, its qualities and the considerations to bear in mind when using it.
Methodology
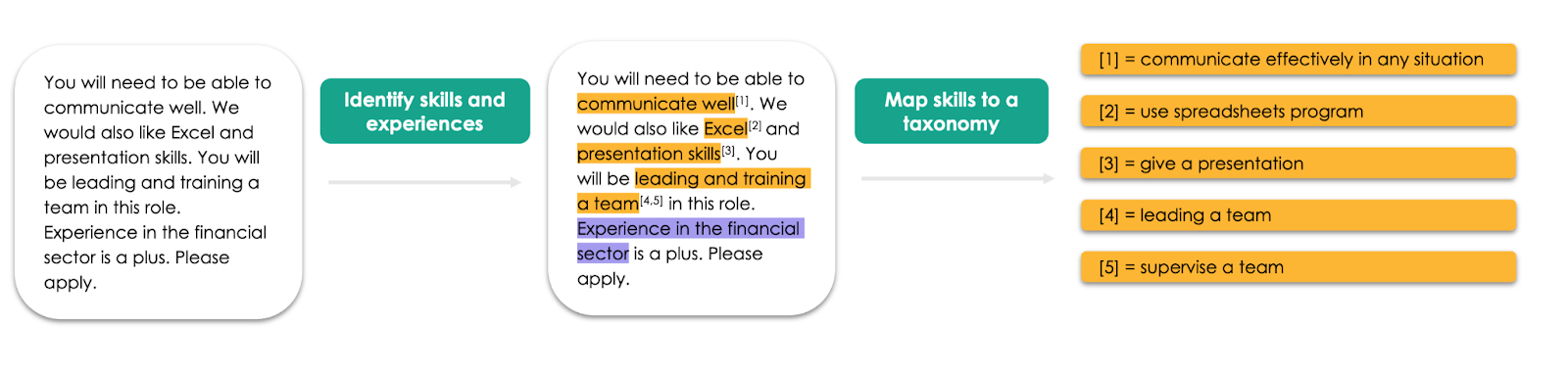
Our approach to extracting standardised skills from job adverts has two steps:
- The first step is extracting skills using a model that predicts the parts (“entities”) of a job advert that are skills. This model was trained using spaCy’s Named Entity Recognition (NER) neural network architecture, which is described here in more detail.
- The second step involves mapping the extracted skill entities from job adverts to an existing taxonomy of skills (such as ESCO). To do this, we find the semantically closest taxonomy skill to each extracted skill entity; for example, “Excel” might be mapped to the ESCO skill “use spreadsheets software”. Semantic closeness is found by numerically representing all skill entities and taxonomy skills using huggingface’s sentence-transformers/all-MiniLM-L6-v2 pre-trained model and then calculating the similarity between these numerical representations.
More detailed information about these two steps can be found in our model cards.
Using the package
You can use the package in two ways:
- If you would like to extract the skills from a single advert and are not familiar with the Python programming language, you can use our user interface tool.
- If you would like to extract skills from a large volume of job adverts and are familiar with Python, then you can use our Python library ojd–daps–skills. More about the usage of this library can be found in our documentation page.
Strengths and limitations of the Skills Extractor Library
Strengths
The strengths of the Skills Extractor library are threefold:
- It can extract skills that have not been seen before. For example, although the ESCO taxonomy does not contain the programming skill “React”, the model was able to detect from the sentence “You have Vanilla JavaScript skills (including React, Node and TypeScript)” that “React” was a skill, and it also mapped it to the ESCO skill “use scripting programming”.
- The library can be adapted to your chosen taxonomy. We have coded the library in such a way that you can map skills to a custom taxonomy if desired. Further details on this option are available in our documentation.
- You can match to different levels of the taxonomy. This can be handy when a job advert mentions a broad skill group (e.g., computer programming) rather than a specific skill (e.g., Python).
To get a sense of how well our algorithm works, we randomly sampled almost 200 skill entities that our algorithm extracted and mapped to ESCO. We then manually went through each of these and judged whether we thought the skill extracted was appropriate, and whether the ESCO skill to which it was matched was also appropriate. We judged that only 6% of the skill entities were inappropriate; one example was “General terms and conditions” being extracted as a skill. Of the 94% appropriately extracted skill entities, 88% were also judged to be appropriately mapped to ESCO skills. As a result, we feel confident in the skills our algorithm extracts and believe that it is competitive with the results of other skill extraction algorithms.
More about the algorithm’s performance, evaluation and comparison to other algorithms can be found in the library’s model cards and metrics documentation.
Limitations
Although our algorithm performed well when we evaluated it for appropriate skills, there are a few nuances which can sometimes produce inappropriate skill entities or taxonomy mappings. It is important to bear these in mind when reviewing results from the model.
Firstly, although the language model used to map semantic meaning can sometimes understand metaphors, metaphors can, on occasion, still cause inappropriate matches. For example, the phrase “understand the bigger picture” would be extracted as a skill entity and then matched to the ESCO skill that is called “interpreting technical documentation and diagrams”.
Secondly, the algorithm can struggle with sentences that contain multiple skills. For example, a job advert may mention the phrase “developing visualisations and apps” which contains the skills “developing visualisations” and “developing apps”. In these more basic examples, the Skills Extractor uses semantic rules to split the phrase into individual skills, such as split “[verb] [object 1] and [object 2]” into “[verb] [object 1]” and “[verb] [object 2]”. However, in more complicated examples the Extractor is not able to apply splitting rules. When this happens, we end up matching the whole phrase to the taxonomy, which sometimes causes skills (within the phrase) to be missed.
Finally, our NER model meets many needs and can be improved. For example, it may extract some entities that are not skills but then get matched to a skill in the chosen taxonomy. For example, in one advert the phrase “assist with the” was identified as a skill entity and was matched to “providing general assistance to people” in the ESCO taxonomy. For this very reason, we recommend that skills extracted should not be used to measure skill demand without expert review and input, nor should they be used for any discriminatory hiring practices.
Conclusions
There is scope for further improvements to the skills extraction algorithm. Future work could include improving the way it splits multi-skill entities into single skill entities or allowing longer skill entities to be mapped to multiple skills in a taxonomy. Another avenue to explore would be training our own sentence embeddings with job-specific texts, which is something that could potentially improve both the neural network model and the taxonomy mapping steps.
Although there are areas for methodological improvement, we feel confident in the results of the skills extraction library as it stands. The library is currently being used in Nesta’s OJO to extract skills from millions of job adverts. We have been able to analyse this data to gain insights into the skills requested by employers, occupational skill similarities and geographic differences in skills. You can read about this in our interactive analysis blog. Future analysis could explore skill differences by industry or, if there was available data, skill demand by age and gender.
We also hope that by open-sourcing the library, others can use it to extract skills from their own job adverts.
Links
Interactive analysis blog ‘Exploring UK Skills Demand’ by India Kerle, Elizabeth Gallagher and Cath Sleeman
Acknowledgements
This research has been funded by the Office for National Statistics as part of the research programme of the Economic Statistics Centre of Excellence (ESCoE). Thanks to the ONS team in particular Sanjiv Mahajan and Gueorguie Vassilev for their expert guidance.
ESCoE blogs are published to further debate. Any views expressed are solely those of the author(s) and so cannot be taken to represent those of the ESCoE, its partner institutions or the Office for National Statistics.
